做完这一切之后,启动 Spring Boot 项目,就会发现数据库中多了一个名为 t_user 的表了。
针对该表的操作,则需要我们提供一个 Repository,如下:
1 2 3 4 5
publicinterfaceUserDaoextendsJpaRepository<User,Integer> { List<User> getUserByAddressEqualsAndIdLessThanEqual(String address, Integer id); @Query(value = "select * from t_user where id=(select max(id) from t_user)",nativeQuery = true) User maxIdUser(); }
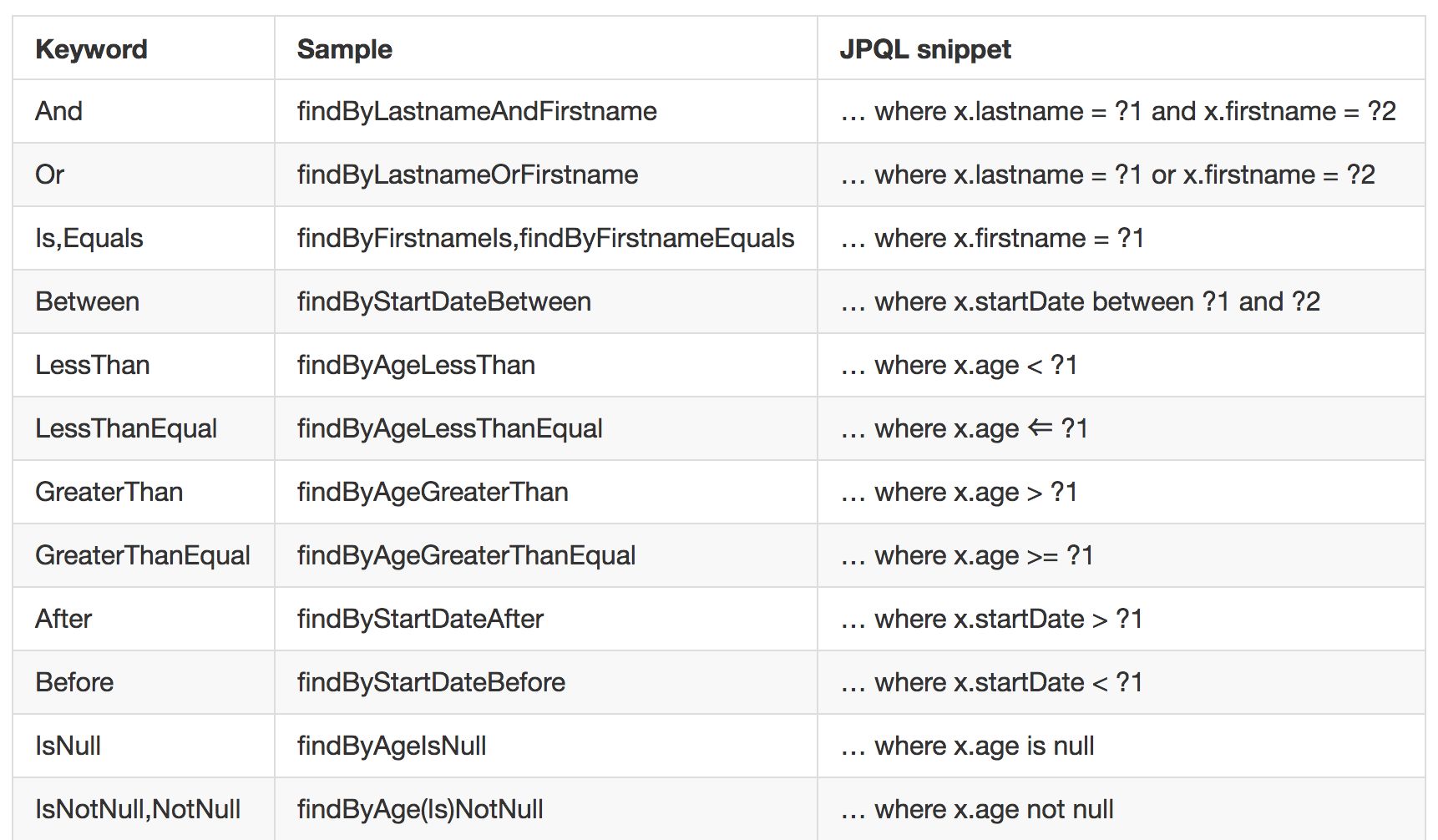
这里,自定义 UserDao 接口继承自 JpaRepository,JpaRepository 提供了一些基本的数据操作方法,例如保存,更新,删除,分页查询等,开发者也可以在接口中自己声明相关的方法,只需要方法名称符合规范即可,在 Spring Data 中,只要按照既定的规范命名方法,Spring Data Jpa 就知道你想干嘛,这样就不用写 SQL 了,那么规范是什么呢?参考下图:
当然,这种方法命名主要是针对查询,但是一些特殊需求,可能并不能通过这种方式解决,例如想要查询 id 最大的用户,这时就需要开发者自定义查询 SQL 了。
@RestController publicclassUserController{ @Autowired UserDao userDao; @PostMapping("/") publicvoidaddUser(){ User user = new User(); user.setId(1); user.setUsername("张三"); user.setAddress("深圳"); userDao.save(user); } @DeleteMapping("/") publicvoiddeleteById(){ userDao.deleteById(1); } @PutMapping("/") publicvoidupdateUser(){ User user = userDao.getOne(1); user.setUsername("李四"); userDao.flush(); } @GetMapping("/test1") publicvoidtest1(){ List<User> all = userDao.findAll(); System.out.println(all); } @GetMapping("/test2") publicvoidtest2(){ List<User> list = userDao.getUserByAddressEqualsAndIdLessThanEqual("广州", 2); System.out.println(list); } @GetMapping("/test3") publicvoidtest3(){ User user = userDao.maxIdUser(); System.out.println(user); } }
如此之后,即可查询到需要的数据。
好了,本文的重点是 Spring Boot 和 Jpa 的整合,这个话题就先说到这里。
多说两句
在和 Spring 框架整合时,如果用到 ORM 框架,大部分人可能都是首选 Hibernate,实际上,在和 Spring+SpringMVC 整合时,也可以选择 Spring Data Jpa 做数据持久化方案,用法和本文所述基本是一样的,Spring Boot 只是将 Spring Data Jpa 的配置简化了,因此,很多初学者对 Spring Data Jpa 觉得很神奇,但是又觉得无从下手,其实,此时可以回到 Spring 框架,先去学习 Jpa,再去学习 Spring Data Jpa,这是给初学者的一点建议。